
Request collapsing
Request collapsing is the practice of combining multiple requests for the same object into a single request to origin, and then potentially using the resulting response to satisfy all pending requests.
This prevents the expiry of a very highly demanded object in the cache causing an immediate flood of requests to an origin server, which might otherwise overwhelm it or consume expensive resources. For high traffic services, correct use of request collapsing will substantially reduce and smooth out traffic to origin servers.
However, since request collapsing causes requests to be queued, in some situations it can slow down response times to end users. If a large number of client requests are waiting on a single backend request, and the response from the backend turns out to be non-cacheable (e.g. because it is private to a single user), each of the queued requests must then be sent to the backend independently. Mechanisms such as hit-for-pass and pass on request can help to avoid this being a problem.
By default, cache misses will qualify for request collapsing in both VCL and Compute services, when using the readthrough or simple cache interfaces. The core cache interface supports request collapsing but only when explicitly configured within a cache transaction.
All possible scenarios in which request collapsing should be considered are laid out below (non-default behaviors in the VCL flow column are shown in bold):
| Scenario | Collapses? | Description | VCL flow |
|---|---|---|---|
| Miss and cache | ✅ | On a typical cache miss, requests will collapse, and where the origin serves a cacheable response, all queued requests will get copies of the same response when it's received from origin. | vcl_recv: lookup ➔ vcl_miss: fetch ➔ vcl_fetch: deliver |
| Uncacheable response | ⚠️ | If a request is a cache miss, and therefore collapses, but the origin returns an uncacheable response, then the response will be used to serve only the request that triggered the fetch, and other queued requests will form a new queue behind the next request in the queue (see WARNING below). | vcl_recv: lookup ➔ vcl_miss: fetch ➔ vcl_fetch: deliver |
| Pass on response VCL only | ✅ | If a VCL service executes return(pass) on a cacheable response in vcl_fetch, then the response will be used to serve only the first request, a hit-for-pass object will be created, queued requests will be individually (and concurrently) forwarded to origin without creating a fresh queue, and future requests will encounter the hit-for-pass scenario. | vcl_recv: lookup ➔ vcl_miss: fetch ➔ vcl_fetch: pass ➔ ... |
| Hit for pass | ❌ | If a request encounters an existing hit-for-pass marker during a cache lookup, it will be forwarded to origin and will not be eligible for collapsing. The response will not be cacheable (regardless of the exit state from vcl_fetch in the case of VCL services). | vcl_recv: lookup ➔ vcl_pass: fetch ➔ vcl_fetch |
| Pass on request | ❌ | If a request is flagged for PASS by return(pass) in vcl_recv or using a Compute CacheOverride, it will be forwarded to origin and will not be eligible for collapsing. The response will not be cacheable. | vcl_recv: pass ➔ ... |
| Explicit disable VCL only | ❌ | If request collapsing is explicitly disabled by setting req.hash_ignore_busy to true in vcl_recv, the request will not be eligible for collapsing and stale objects become unusable (disabling stale-while-revalidate and stale-if-error directives). However, in contrast to a pass on request, the request will be eligible to be satisfied from cache, and if it does get forwarded to origin, any resulting origin response will be cacheable. | Any |
Request collapsing applies to each origin request individually, and so is not affected by services that make multiple origin requests (via restart in VCL services or by executing multiple fetches in a Compute program).
WARNING:: If a request is subject to request collapsing, and the origin response is not cacheable, then the response cannot be used to satisfy queued requests, AND we also cannot create a hit-for-pass marker. In this situation the next request in the queue will be sent to origin and the remaining requests will form a new queue, resulting in the requests being sent consecutively, not concurrently. In some cases this can create extreme response times of several minutes.
To avoid this bottleneck behavior, ensure that wherever possible, the request skips the cache entirely, and otherwise, that responses are always cacheable. When you don't want to actually cache them, pass on response (in VCL services return(pass) in vcl_fetch).
Without request collapsing - the cache stampede problem
Request collapsing is important because in practice the interval between requests for the same object is often smaller than the time required to fetch the object from origin. For example, the home page of a popular website might be requested 50 times per second, but might take 500ms to fetch from origin, including the network latency and origin processing time. Without request collapsing, the origin would be required to generate the same page multiple times concurrently:

This might not be a problem if the number of concurrent requests is small, but for an object requested 50 times per second, with a 500ms fetch latency, the origin would be processing 25 concurrent requests for the same object before Fastly had the opportunity to store it in cache. This may also mean that where an object is already in cache, the moment it expires or is evicted the origin server will receive a sudden deluge of requests and become overloaded. This kind of effect is often called a cache stampede problem.
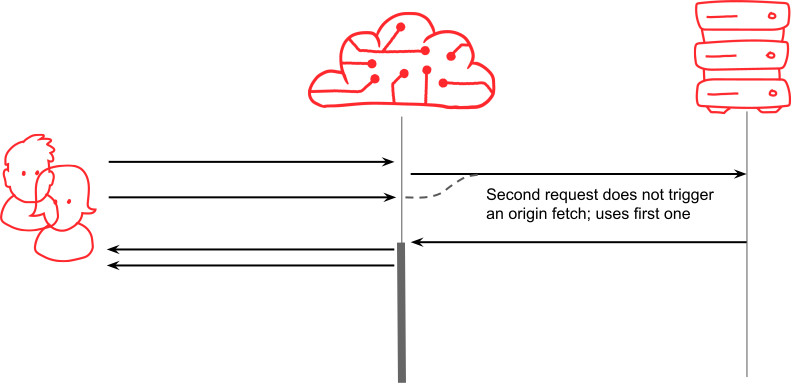
The waiting list mechanism
The answer is to have a queue, which Fastly calls a 'waiting list'. When the second request arrives, we know that we’re already in the process of fetching the resource that they want, so instead of starting a second fetch, we can attach user 2's request to user 1’s. When the fetch completes, the response can be saved in the cache, and also served simultaneously to both waiting users (and anyone else that’s joined on in the meantime).
Pass on request
If you know before making a backend fetch that the response will not be cacheable, exclude it from request collapsing by marking it to pass the cache.
Uncacheable and private responses
Request collapsing is essential to manage demand for high-traffic resources, but it creates numerous edge cases and exceptions that have to be addressed. The first and most obvious is what happens if the resource, once it arrives from the origin, is marked private.
Cache-Control: privateHINT: One of many reasons you should be using Cache-Control and not Expires for your caching configuration is the ability to use directives like private. The private directive tells Fastly that this response is good for only one user, the one that originally triggered the request. Anyone else that got tagged onto the queue must now be dequeued and their requests processed individually.
Responses not marked private, may be used to satisfy queued requests. Even a response with max-age=0 or no-cache (which are semantically equivalent) can be used to satisfy all the waiting clients, and the next request for the object will once again be a MISS. If your reason for giving a response a zero cache lifetime is that it contains content intended for a single user only, then ensure it is correctly marked private to avoid having this content sent to more than one user.
Hit-for-pass
When a private cache-control directive or custom edge logic causes a pass on response scenario, it prevents a response from being used to satisfy the clients on the waiting list, and triggers some of the queued requests to be dequeued. Since the cache state may have changed, each of these queued requests will now check cache again, and if they don't find a hit, they will all be sent to origin individually. However, whether this is done concurrently or consecutively depends on whether the pass response from vcl_fetch is cacheable.
If the pass response is cacheable, then a marker is placed in cache that says “don’t collapse requests for this resource”, called a hit for pass object. Requests already queued and future incoming requests will now hit that marker, disable request collapsing, and trigger fetches to the origin immediately, which will not block or affect each other. Hit-for-pass objects have a 2 minute TTL by default, but will respect the response's defined TTL, subject to a minimum of 2 minutes and a maximum of 1 hour (so a TTL of zero will still set a hit-for-pass object for long enough to allow the queued requests to be dequeued and processed concurrently). Each completed request will dequeue more of the waiting requests until the waiting list is empty.
HINT: Even though a hit-for-pass object is an efficient mechanism for managing objects that cannot be served from cache, it's even better to pass on request to avoid building a waiting list in the first place. If you can predict (ahead of talking to an origin server) that a request should be passed, flag the request appropriately by executing return(pass) from vcl_recv in VCL services, or use a CacheOverride in Compute services.
If the pass response is not cacheable, then the queued requests are still dequeued, but the first one to create a new fetch to origin will set up a new waiting list and the other requests will most likely join it. If the result of that fetch is also not cacheable (likely) then this process repeats with only one request for the object proceeding to origin at a time. This may result in client side timeouts for popular objects, so the use of hit-for-pass is highly recommended.
IMPORTANT: Hit-for-pass objects respect the Vary header just as normal cache objects do, so it's possible to have a single cache address in which some variants are hit-for-pass, and others are normal objects.
Streaming miss - collapsing during response phase
Typically, duplicate requests are most likely to arrive while the first request is being processed by the origin (the request phase). However, when the origin starts transmitting the response, it doesn't always arrive all at once, and may actually take a long time to download. In the case of large files, slow connections, or streams (e.g., video or push messaging), downloading the response may take minutes. In this case, duplicate requests are actually more likely to be received during the response phase, after the response has begun to be received by Fastly.
These new requests may still be able to 'join' the in-progress response rather than initiating a new request to origin, and whether they can do so depends on whether the response is fresh (i.e. has a positive remaining TTL) in the cache when the new request is received.
- CDN services
- Compute services
In a VCL service, enable streaming miss for a response by setting beresp.do_stream.
Fastly evaluates a response to determine its cacheability and TTL as soon as the response headers are available. Then, if streaming miss is enabled, the partial response will be written to the cache immediately, a clock will be started to track the object's cache lifetime, and as new data is received it will be appended to the cache object until the origin response is complete. If streaming miss is disabled, the entire response will be collected and written to the cache when it is complete.
Therefore, if streaming miss is disabled, there is effectively no response phase. Requests for the same URL that arrive after the first one will continue to form the same queue until the origin response is complete, and only then will that response be used to satisfy the waiting clients. It will then continue to be used to satisfy future requests for that URL, as a cache HIT, until its TTL expires.
If streaming miss is enabled, the cache lifetime begins as soon as response headers are available, and any new requests for the same URL that arrive after that point will result in one of two outcomes:
- If the in-progress response was not cacheable or has already become stale, the new request will be a MISS, will trigger a new request to origin, and potentially start a new waiting list.
- If the in-progess response was cacheable and is still fresh, the new request will receive all the response data we have buffered so far, and will then receive a copy of any new data that arrives until the response from origin is complete.
NOTE: When streaming miss is enabled, each client receiving a copy of the same streamed response from origin will execute its own edge code concurrently in isolation, and will have a separate output buffer, accounting for the fact that each client may be capable of receiving data at a different rate.
HINT: As an example: A request is a MISS and triggers an origin fetch with streaming miss enabled, and the origin responds in 2 seconds, with a header block that includes Cache-Control: max-age=30. The rest of the response takes 60 seconds to download, because the origin server is streaming it from a live source. Here's what would happen to subsequent requests for the same URL:
- 00:01 After one second, a second request arrives. There is already an in-flight request to origin which has not yet produced a response so this new request is a MISS and starts a waiting list rather than initiating a separate fetch.
- 00:02 At two seconds, the origin starts responding. We create a cache object with a 30s TTL immediately because streaming miss is enabled, and use that cache object to satisfy the waiting list. Both clients now start to receive copies of the same response stream.
- 00:20 At twenty seconds, a new request is received. There is already a cache object for this URL, so this is a cache HIT, but the response is incomplete. This new client will receive everything buffered in the cache so far, and the response will then be a copy of the continuing response stream from the origin.
- 00:30 The cache object expires. The origin is still sending data, and the clients already connected to that stream will continue to receive it.
- 00:40 At forty seconds, a new request is received. This request is a MISS because there's no fresh object in the cache (even though there IS an active response still streaming that URL to 3 clients). This request will create a new fetch to origin, which will run concurrently with the now-stale one.
Long queue times and cascading failures
Once a request joins a waiting list, the amount of time it has to wait depends on how long the in-progress fetch takes, and how it resolves. The time limit on the fetch can be controlled via backend properties such as between_bytes_timeout, connect_timeout, and first_byte_timeout.
Fetches can resolve in a number of ways that will have different impacts on how resources in the queue end up resolving:
- If a fetch results in a new object in cache (in VCL services,
beresp.cacheableis true,beresp.ttlis positive andvcl_fetchends withreturn(deliver)), the entire waiting list can be satisfied using that new response, and all clients can be served a response immediately. - If the fetch results in a hit-for-pass (in VCL services,
beresp.cacheableis true,beresp.ttlis positive andvcl_fetchends withreturn(pass)), then the entire waiting list will collapse and all requests on it will be sent to origin separately and concurrently. In this situation, each client will experience latency equal to the duration of the request they waited on plus the duration of their own backend fetch. - If a fetch times out, errors, or otherwise produces an uncacheable response (
beresp.cacheableis false orberesp.ttlis zero, or there's a network error), then some of the queued requests will be taken off the queue and processed - likely creating new fetches and new queues because there is no hit-for-pass object in the cache to prevent queues forming. If those in turn take a long time, this will continue to exacerbate the length of time objects are held in queues, and an average user might have to wait for many sequential backend fetch attempts to complete before they get a response (which may be an error).
Imposing a maximum wait time
When a request comes off a waiting list but cannot be satisfied by the fetch that it was waiting on, it will trigger vcl_miss and a new fetch will be made. However, if the request has been waiting a long time, it might be better to fail such requests quickly, returning a suitable error such as a 503 (service unavailable) to the client device, rather than leaving them in a lengthy queue. You can do this by adding a condition to the vcl_miss subroutine that checks how long the request has been queued in the waiting list:
if (time.elapsed > 1s) { error 601 "waiting too long"; }This has the benefit of generating more failures more quickly, which causes waiting lists to disassemble faster in cases of timeouts or origin errors. The result will be a much faster and more predictable end user latency, and much lower origin traffic when the origin is exhibiting problems, at the expense of a potentially slightly higher number of errors that end up being delivered to the user.
When combined with synthetic in vcl_error and serving stale, this can improve both performance and reliability of end user experience dramatically.
Interaction with clustering and shielding
Requests may arrive on any one of Fastly's edge servers. The cache lookup process (vcl_hash in VCL services) determines a cache address for each object, and typically, will forward the request from this initial server (the delivery server) to another server in the POP which is responsible for the storage of that specific object (the fetch server). This process is called clustering-in-vcl and is intended to increase cache efficiency, and also to reduce the number of requests that will be forwarded to origin, because all the fetches for a particular object will be focused through a single cache node that will then efficiently collapse them into a single origin request. Internally, Fastly also operates request collapsing between the delivery nodes and the fetch node to efficiently balance load in the event that one single URL is experiencing an extremely high rate of requests.
Disabling clustering therefore has the potential to significantly increase traffic to origin not just due to a poorer cache hit ratio, but also due to the inability to collapse concurrent requests that originate on different delivery servers.
Shielding routes requests through up to two Fastly POPs before they reach your origin server, first the POP closest to the end user, and then a nominated second location which is typically physically close to your origin. In this scenario, requests from POPs across the Fastly network are focused into a single POP, allowing it to perform request collapsing before forwarding a single request to origin.
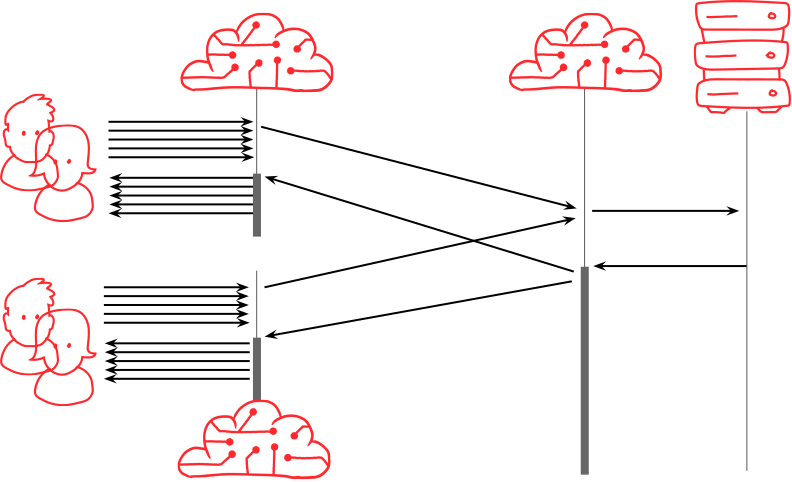
The combination of clustering and shielding creates up to four opportunities for Fastly to collapse requests, and is an efficient way to dramatically reduce origin load for highly requested objects on high traffic sites.
