

In recent years, the frequent occurrence of data breaches and credential dumps has become an unfortunate reality. Due to the common mispractice of credential reuse, cybercriminals are often able to make use of compromised credentials to perform an account takeover (ATO) attack. A technique commonly used to perform an ATO attack is called credential stuffing.
What is Credential Stuffing?
Credential stuffing involves enumerating through lists of compromised credentials in an attempt to gain unauthorized access to customer accounts.
Fortunately, since we also have access to compromised credentials in the form of password hashes, we can detect these kinds of attacks and stop them. The password hashes are made available by “HaveIBeenPwned” (HIBP), a community service that maintains a database of compromised passwords and provides APIs to verify if a password is compromised in a privacy-preserving way. In this post, we will discuss a low latency approach to detect these attacks by co-locating the password hashes in a KV Store, along with Compute on Fastly’s edge.
Billion Credentials Attack
According to HaveIBeenPwned, as of Feb 2024, the number of compromised accounts stands at 12.94 billion. That’s the total number of known leaked accounts across many compromised websites. Some of these might be using the same credentials (i.e. combination of username and password) in multiple websites. This is the credential reuse we mentioned earlier; for instance, using the same user+pass combination for Google and Yahoo. Also, credentials that have different usernames, could be using the same passwords as well. This results in a much smaller number of unique passwords, compared to the 12.94 billion account mentioned above.
In our analysis of the HIBP passwords dataset, the service hosted 931 million unique passwords. Since the data set also includes the frequency of use for each password we can infer, these correspond to 6.93 billion credentials, suggesting that on average a credential pair is used for 2 accounts (i.e. 2 websites).
Some passwords are used a lot more than others. For instance, the password ‘123456’ was found in 42 million credentials, whereas ‘hunter2’ was used only in 24,000 credentials. The below chart plots the total count of credentials corresponding to the number of passwords sorted by how frequently each password is used. Surprisingly, just 34 million passwords (or 3.6% of the compromised passwords) are used in 60% of compromised credentials, suggesting massive password reuse. This is both users reusing the same credentials in multiple websites, and also unrelated people using the same passwords (with different usernames).
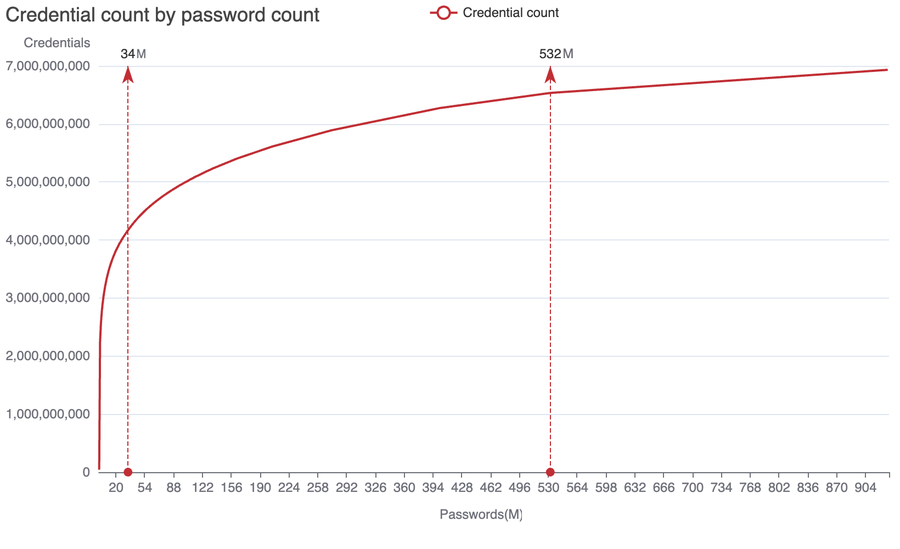
Figure 1: Credential counts for passwords from the HaveIBeenPwned password hashes dataset
Similarly, 532 million passwords (57% of compromised passwords) are used in 94% of compromised credentials. The linear 1:1 growth beyond this point indicates the rest of the 400 million passwords are unique and likely generated by password managers, and hence not useful for criminals in a credential-stuffing attack. With 6% attributed to password managers, that still leaves 94% of credentials provably useful for credential-stuffing attacks. That’s at least 6.53 billion credentials out there available for credential-stuffing attacks!
How to Detect Credential Stuffing Attacks
Using password managers to generate and authenticate with unique passwords for every website completely removes the possibility of credential-stuffing attacks. While the chart above plots compromised credentials, the size of the dataset is large enough to be representative of uncompromised credentials as well. So we can deduce that the adoption of password managers has been quite low, with only about 6% of the credentials using them.
Implementing multi-factor authentication (MFA), with proper registration and reset procedures, is also an effective mitigation against credential stuffing and other forms of account takeover attacks. The recently introduced Passkeys standard is a more convenient and secure mechanism for sign-in, removing passwords completely out of the picture. While this method of sign-in is currently under adoption, we recommend using passkeys wherever they are supported.
When such mitigation methods are not possible, it’s important to detect the attack proactively to stop it. NIST guidance for “memorized secrets” recommends comparing passwords to “passwords obtained from previous breach corpuses” during login, signup, and password reset.
In an earlier post, we described an approach to using the HIBP Passwords API from the Fastly Compute service to be able to detect compromised passwords in requests. In this post, we describe a novel approach for this detection, done completely at the edge, without invoking the Passwords API for each request. Instead, we rely on a highly compressed form of password hashes stored at the edge. As a result, the new approach is much quicker and avoids relying on third-party availability.
Compromised passwords at the edge
The low latency access to the HIBP data set is achieved by storing the password hashes on the Fastly KV store. A KV store is a type of container that allows you to store data in the form of key-value pairs for use in high-performance reads and writes at the edge. The KV store supports an unlimited number of keys, with a maximum key size of 1024 bytes in UTF-8 format. The values can be text or binary with a maximum size of 25MB.
Unfortunately, the HIBP passwords dataset is a massive list of SHA1 hashes of compromised passwords, which is currently about 40 GB in size in uncompressed text form and growing.
Optimizing further with filters and partitions
We persist the HIBP dataset as a filter data structure instead of the uncompressed text form to reduce resource consumption (KV store and Compute memory) and to enable low latency access from Fastly Compute. Filters are probabilistic data structures that use hash functions to randomize and compactly represent a set of items. The key property of filters is the possibility of false positives, without any false negatives. In other words, there is a possibility, albeit very low, of incorrectly identifying a password as compromised, but a compromised password will always be correctly identified as compromised. By representing the hashes in a filter data structure, we reduced the size of the dataset by 97%, from 40 GB to 1.08 GB.
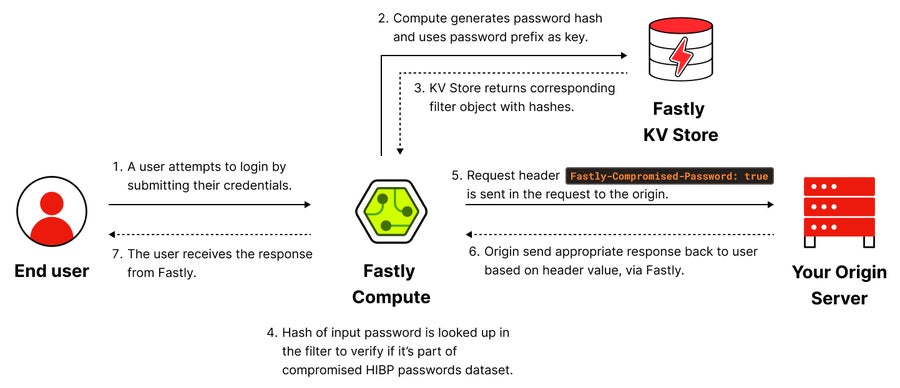
Figure 2: Requests are intercepted by the Compute service to check for compromised passwords
To further reduce resource consumption, password hashes are grouped using a 3-character prefix, with a separate filter for each prefix. These filters are stored as values in the KV Store keyed by the 3-character hash prefix. Only the filters for the prefixes that are relevant to the password being checked are loaded into the Compute service – typically about 266KB each.
When a request containing a password is made, the Compute service generates the SHA1 hash for the password and uses the first three characters of the hash to retrieve the appropriate filter object from the KV store. We looked at the password hash in the filter to determine if the password was compromised. We add an additional request header “Fastly-Compromised-Password” with the results and forward the request to the backend origin. This allows the backend to modify its behavior based on the password’s compromised status. If the password is compromised, the backend can choose to reject the password (e.g., on sign up), redirect the user to a password reset page (e.g., on login), send a signal to a credential stuffing detector, or take other appropriate actions.
We experimented with several filter algorithms including Cuckoo filters, XOR filters, and BinaryFuse8 filters, along with varying lengths of hash prefixes for data partitioning in the KV store. Considering lookup performance, size of generated filters, growth patterns in filter size with data growth, and filter unmarshaling speed, we found 3 character prefixes with BinaryFuse8 filters with 9-bit fingerprints to be the sweet spot. With this fingerprint size and load factors for this dataset, the estimated false positive rate for the filter is about 0.3%.
Demo and source code
We have released a demo of this approach in the demos section of the Fastly Developer Hub. Go ahead and try this out for yourself and watch the real-time log viewer for the sequence of execution in the Compute service. Figures 3 and 4 below show an example of running the demo with the weak password ‘hunter2’.
Figure 3: The credentials are accepted in clear text for the purpose of the demo
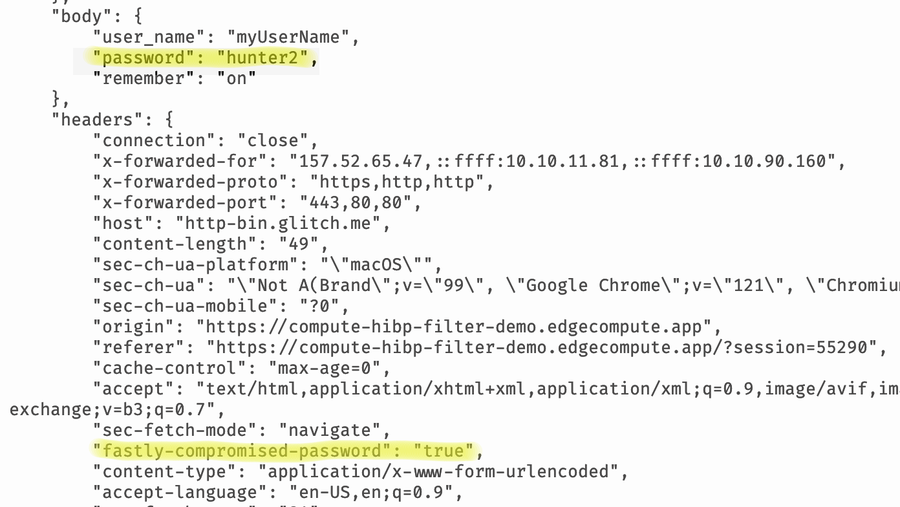
Figure 4: The request sent to the backend is enriched with the “Fastly-Compromised-Password” header
We have open-sourced the code for the demo, so you can implement the compromised password detection on your website. The repo also includes code to build filters for the hashes and upload them to the KV store. We recommend regenerating the filters once a quarter to keep them updated.
Fastly Next-Gen WAF has built-in detection for compromised passwords, allowing customers to use the COMPROMISED-PASSWORD signal from templated rules to identify credential-stuffing attacks at login endpoints and help users avoid using compromised passwords during registration.